
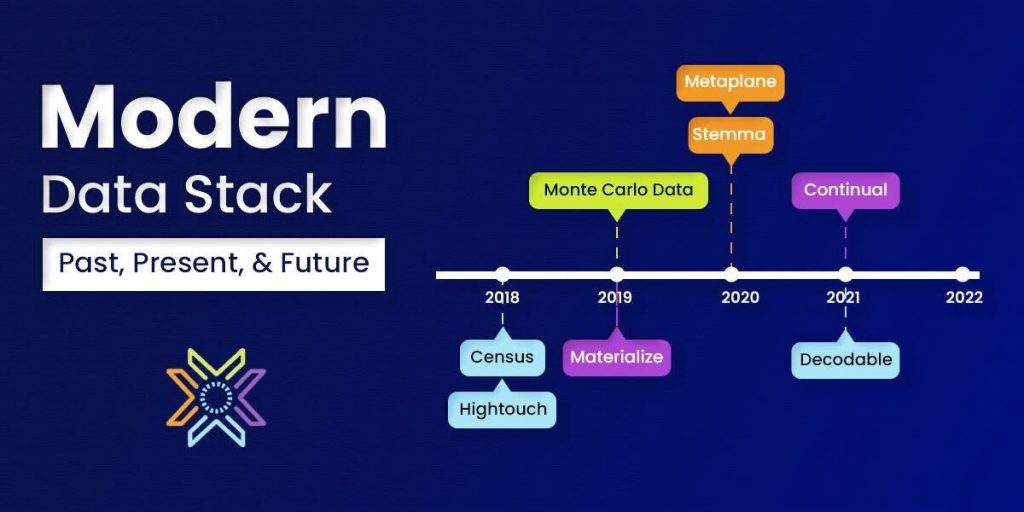
What is the Modern Data Stack?
A group of technologies that comprise a data pipeline is referred to as the modern data stack. It enables businesses to gather data from multiple data sources, push it into a data warehouse, and connect the data warehouse to a business intelligence tool for tasks like data visualization to speed up decision-making.
In this blog post, we will discuss the past, present, and future of modern data stack, and more.
How the Modern Data Stack Was Formed
Present Modern Data Stack Architecture
-Data Ingestion
-Data Warehouse
-Data Transformation
-Business Intelligence
-Data Governance
-Data Orchestration
-Reverse ETL
Why is Modern Data Stack a Failure?
What’s Next?
-Knowi Approach
Conclusion
How the Modern Data Stack Was Formed
The modern data stack’s function is to enable an organization to centrally store and pass along all of its data to data analysts and engineers who will organize, clean, and analyze it to serve the business’s needs. This requires a countless number of tools and processes which over-complicate a business’s operations.
Previously, organizations needed to buy old servers and hardware that could be housed and operated on their own premises with their own infrastructure in order to become data-centric. As time went on, mass digitization increased the need for a streamlined data solution.
Increasing interest and demand to access and control business data have even grown among teams outside of IT. Marketing teams are fantastic examples. They require data to survive, but the issue was that IT had difficulty delivering insights in a timely manner.
Some major challenges included high cost, complicated setup, maintenance costs, adequate scalability & flexibility, managing performance management, security, & troubleshooting with the on-premises as well as the traditional data stack (TDS).
Amazon introduced its Amazon Web Services (AWS) in 2006, providing a range of cloud services to other businesses. This allowed users to access remote storage and connect to virtual machines.
The following year, IBM, Google, and other US institutions collaborated to create server farm projects that dealt with massive data volumes and needed efficient processors.
Businesses required a more adaptable solution that provided greater control over their data. October 2012 served as a turning point when Amazon unveiled Redshift, a cloud-based Data Warehouse (DWH) solution.
Modern Data Stack (MDS) tools such as Google BigQuery and Snowflake were made possible as a result.
Present Day Modern Data Stack Architecture
Companies utilize very different modern data stack architecture designs and technologies. Nevertheless, any data stack has the following components:
Data Ingestion
The process of importing data into a data store, such as a data warehouse for archival and analysis, is known as data ingestion. Knowing the data sources your company uses is the first step in building a modern data stack. Data ingestion tools are used to transfer your data.
Some of the most popular tools in this category are Hevo, Fivetran, Airbyte, and Stitch.
Data Warehouse
An organization can store and organize its data in one location called a data warehouse. The usage of conventional relational databases, which were designed to hold structured data, has proven to be difficult in situations with high volumes of data.
NoSQL databases are appropriate for the storage of unstructured data, but because they are incompatible with the majority of tools used in hybrid settings, they can be challenging to deploy.
As they provide their own managed solutions, businesses have switched to cloud data warehousing solutions to find a way around these restrictions. For object storage, AWS offers the Amazon Simple Storage Service (S3). BigQuery is a component of Google’s cloud computing infrastructure. These services offer low-latency storage solutions for massive amounts of data.
Snowflake, BigQuery, Databricks, and Redshift are common tools used by businesses to build out their data warehouses.
Data Transformation
In the Modern Data Stack, the process of converting, cleaning, and formatting a document from one format or source system—for example, an Excel spreadsheet, an XML spreadsheet, or a CSV document—to another, specifically one required by the destination system, is referred to as data transformation.
As it prepares data for additional analysis, visualization, and reporting, data transformation is a vital step in the data integration process. Any sort of dataset can be transformed, regardless of how it was originally labeled or formatted.
DBT, Improvado DataPrep, RestApp, Alteryx, Matillon, and MCDM are examples of data transformation tools.
Business Intelligence
Business intelligence is the process of integrating a range of applications and platforms, including business analytics, data mining, data tools, data infrastructure, and data visualization, with best practices to help organizations make better decisions.
Companies may minimize inefficiencies, adjust to market changes, respond to shifting consumer behavior, manage supply variations, and promote change with the use of comprehensive data.
However, for this to be viable, decision-makers must have easy access to and comprehension of the data. The Modern data stack specifically assists enterprises in achieving this.
Data Governance
Data governance’s goals include making corporate systems’ data available, safe, and compliant with internal standards and regulations while also regulating data use. It guarantees the consistency, dependability, and security of data. Regulations surrounding data governance have compelled businesses to develop new methods for safeguarding their data and rely on data analytics to improve choices and expedite operations.
Data catalogs and data privacy tools are used to implement data governance. Data privacy helps businesses become legally compliant by addressing issues like breaches of sensitive data, while data catalogs assist organizations in tracking and making sense of their data to increase discoverability, quality, and sharing.
Data Orchestration
There are several layers and pipelines in the current data stack. It can be challenging to manage the dependencies across several levels, plan jobs, and keep an eye on the data flow. Data orchestration can help with that.
Data orchestration creates workflows and automates procedures within a data stack. Data orchestration aids in the definition of activities and data flows with a variety of dependencies by data teams.
The idea of directed acyclic graphs (DAGs), or tasks, is used in data orchestration to depict the interdependencies and connections between various data flows. Data orchestration helps Data Engineers in defining the execution, retry, and completion of operations. It is simple to build, schedule, monitor, and execute jobs in the cloud using data orchestration.
Reverse ETL
The data integration methods ETL (Extract-Transform-Load) and ELT (Extract-Transform-Load) enable companies to extract data from external sources and store it in the desired location, such as a data warehouse. Taking data from Salesforce, HubSpot, or Klaviyo and loading it into your preferred location, such as Snowflake or BigQuery, is an illustration of that.
Reverse ETL involves extracting data from the data warehouse and transforming it to conform to the specifications of a third-party system before loading it for further use. To do this, you would take the data from Snowflake or BigQuery and load it into Salesforce, HubSpot, or Klaviyo.
A single, complete data source that offers a unified picture of a company’s data can be created by users with the aid of reverse ETL. It facilitates operational analytics and makes the current ETL operations more efficient. The Reverse ETL operations take place at predetermined periods.
Why is Modern Data Stack a Failure?
Data transportation tools, data warehouses, transformation tools, BI tools, Data Catalogs, Governance tools, ML tools, etc. make up a typical business’ data stack.
Due to the requirement for several tools, consumption-based models, and staff to manage and maintain each, costs for organizations have skyrocketed.
Businesses frequently express frustration with the length of time it takes to obtain insights, the total cost, the complexity, and even the inability to develop embeddable, customer-facing products that are driven by data. Even because of the numerous tools, procedures, and participants, commercial decision-making has become slow. This is also known as the ‘summer of discontent’.
What’s Next?
One end-to-end platform that covers all of these tools’ features is the answer to complexity and extra expenditures. One example of such a platform is Knowi.
Knowi Approach
Knowi is the first analytics platform that natively supports and understands both traditional and non-traditional structures. Using structured data, data engineers may quickly see insights without moving or transforming the data first.
By retaining existing data and obviating the necessity for data and ETL prep, Knowi dramatically cuts the price, time to market, and the difficulty of your analytics initiatives.
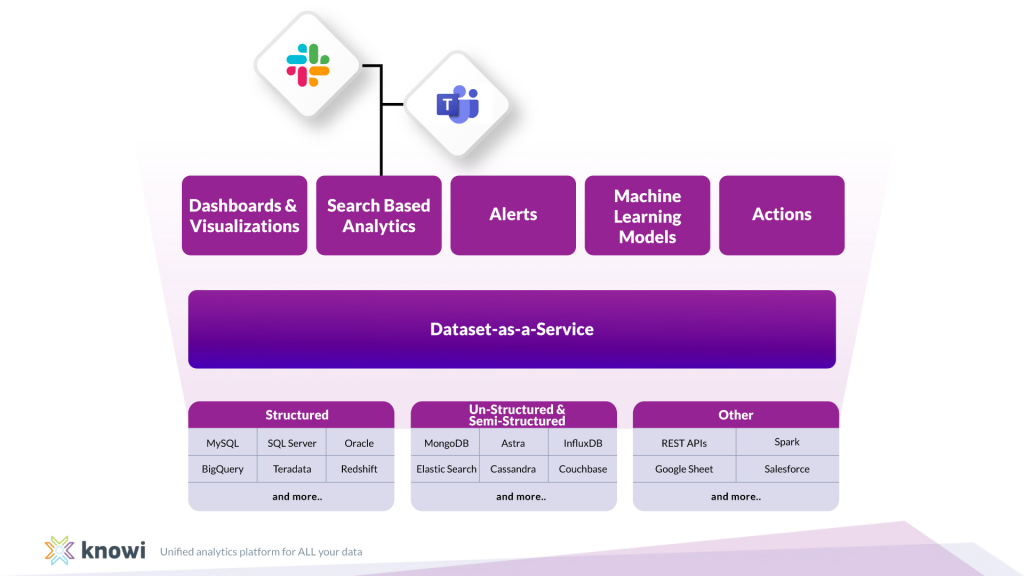
Knowi is a part of the new wave of analytics tools designed specifically for contemporary data stacks. Knowi establishes a native connection to your data source(s), runs a schema-on-read to rapidly identify data, and enables you to begin displaying your data using more than 30 visualization options in minutes.
Knowi securely offers enterprise business intelligence to everyone, everywhere, at any time, with options for cloud, on-premise, or hybrid implementation.
All in all, Knowi is a platform for unified analytics without the requirement for unified data. It does away with conventional ETL and the need to keep raw data in a data warehouse.
It can connect data from several sources and communicate in real time with any data source natively, including SQL databases, NoSQL databases, cloud services, and APIs. Additionally, Knowi offers BI capabilities and analytics based on natural language search.
Conclusion
With a modern data stack, it is difficult to make data actionable due to the need for numerous tools, complexity, and high costs. Business teams are consequently compelled to wait for IT to provide schemas and modify unstructured data in order to fit it back into relational structures.
To solve all these problems, Knowi offers analytics on multi-structured data as the quickest approach to give the business a unified view of enterprise data, automates data-driven actions with programmable triggers, and moves beyond insights to predictive analytics and prescriptive actions.





